Performance
This page gives an overview about the CISC versus RISC discussion, describes some of the weaknesses of the NS32532 CPU microarchitecture and presents some floating-point performance numbers based on the Linpack benchmark.
CISC versus RISC
In the 1980's an intensive discussion arose about the question "how to build the best performing CPU". The new sight was concentrating on the slogan "keep it simple". Traditional CPUs were build according to the principles of CISC : Complex Instruction Set Computer. IBM, Digital Equipment and all the other system vendors build CISC machines based on many small chips. Also the first 16-bit microprocessors were CISC designs.
The main characteristic of CISC is a rich instruction set with a lot of addressing modes. Also operand sizes varies from single bit to blocks of data stored in memory. The heart of the CPU is a state machine which is executing microcode. This microcode is stored in a ROM. If later a bug is found in the CPU it may be sufficient to change the ROM content. This requires only one mask change which is cheaper and faster than a full redesign. The idea behind CISC is to translate any statement in a high level programming language like C to an machine instruction. The result is a compact program code which does not need a lot of expensive main memory.
But this concept has drawbacks. Development cycles of this CPUs became very long and it was difficult to achieve high clock frequencies to improve performance. Therefore out of academic research came a new concept : Reduced Instruction Set Computer or RISC. Studies at the universities have shown that most of the complex instructions were only used infrequently. And even worse a sequence of simple instructions was often found to be faster than a complex instruction doing the same.
The semiconductor technology of the 1980's was not able to integrate millions of transistors. Wafer size was small which limited the size of a chip. Large chips also suffered from lower yield. Especially the microprocessor architects and designers had to fight with the limited transistor budget. Of course anything done in hardware is faster than any software solution. But is a feature worth to be done in hardware or not? Endless discussions must be the daily business in this years.
The RISC friends said : make the design simpler and this will result in higher clock frequencies. Take a large register file and save memory cycles. If there are transistors left over build a cache with it. And the rest is done in software. With this radical approach two famous RISC architectures were born : the MIPS predecessor RISC-1 at Stanford and SPARC at UC Berkely.
For all the established vendors the sitution became difficult. Their main focus was software compatibility : the next generation of machines must be able to run the old software. Therefore switching the architecture to a new concept was not an option. But new machines have to be faster. And the number of transistors was still limited. The NS32532 CPU shows in my opinion the antagonism of the designers : it is a fast chip for simple instructions and a slow chip for real CISC instructions. I will give later on this page some examples.
The story of the NS32764 CPU goes in the same direction (see NS32764 Description). First the designers wanted to change the basic Series 32000 architecture. Later the new CPU became compatible to its predecessors. For sure this decision has taken time and energy. The result obviously was that the NS32764 was to late for the market. Finally this killed the Series 32000 family as a general purpose computer architecture.
Some 20 years later we know what happened to CISC versus RISC : it is history. Both concepts are used in today's most succesful microprocessors. Semiconductor technology was able to shrink the size of a transistor nobody could imagine at the beginning of the 1990's. Billions of transistors can now be integrated. My impression is that engineers of today are no longer forced to make difficult design decisions. If a feature increases the performance take as much transistors as you need.
ASH/LSH/ROT
This group of Series 32000 instructions perform shift operations. LSH means "Logical Shift", ASH means "Arithemtic Shift" and ROT means "ROTATE". The instructions have two operands : the first operand defines the shift count and the second operand is the shifted value. A positive shift count specifies a left shift; a negative shift count specifies a rigth shift. The only difference between LSH and ASH is when the shift count is negative. Then the high-order bit positions emptied by the shift are filled with the sign bit in case of ASH and with "0" in case of LSH.
For example this instructions were used if an operand is multiplied by 2, 4, 8, etc. . Then a left shift is faster than an integer multiplication. If an operand is divided by 2, 4, 8, etc. a right shift is much faster than an integer division.
The NS32016 CPU was not very fast for this instructions. An operand was shifted by one bit position in one clock cycle. Therefore the execution time depends on the shift count. The NS32532 CPU is much faster. It uses a special logic circuitry : the "barrel shifter". This shifter always needs the same amount of time regardeless of the shift count.
| Instruction | NS32016 | NS32532 | M32632 |
|---|---|---|---|
| LSH | 14 - 45 | 3 | 1 |
| ASH | 14 - 45 | 9 | 1 |
| ROT | 14 - 45 | 7 | 1 |
In the table above the number of clock cylces for each instruction is presented. It is a best case number : both operands are in a register. But what is happening inside the NS32532? 3 clock cycles for LSH is a big performance boost. Although ASH is very similar to LSH it consumes three times more clock cycles. What is the reason? For sure somebody knows. Will he share his knowledge with us ? ROT also needs more clock cycles than LSH. Maybe in this case the barrel shifter is used two times to perform a rotate operation.
The good message about the M32632 : all shift instructions need one clock cycle. It was not necessary to spent much effort to achive this result.
CBIT/IBIT/SBIT/TBIT
The "bit" instructions of the Series 32000 architecture are CBIT = "Clear Bit", IBIT = "Invert Bit", SBIT = "Set Bit" and TBIT = "Test Bit". The instructions use two operands. The first operand defines the bit offset and the second operand defines the base address. The operation does the following : the bit [bit offset mod 8] in byte [base address + (bit offset div 8)] is modified or tested. "bit" instructions are typical CISC instructions. In my opinion it should not be very difficult to implement them efficiently.
Thanks to the far-sight of the architects at National Semiconductor a special version of SBIT and CBIT exists : SBITI and CBITI. The "I" identifies the "interlocked" option. A special pin at the CPU informes external control circuits that the execution of this instruction should not be interrupted. During this time intervall the CPU reads the operand, modifies it and writes the result back. This special behavior is especially useful for process synchronization in multiprocessor systems.
So far so good. One can assume that the design engineers put some effort in to execute this instructions quickly. Really ? You should better read the Application Note No. 611 on the Documents page.
On page 4 the title "4.1.1 Replacing the "SBIT" instruction" tells no good news. The author replaces the SBIT instruction by a sequence of instructions and tells the reader : "this is faster!". The author is not talking about the NS32016 CPU which suffered from the limited number of transistors. He talks about a third generation CPU which should be better than the first generation in any way! This is exactly what the RISC friends claim : "a series of simple instructions is faster than a single complex instructions".
Because the NS32GX32 CPU is a spin-off of the NS32532 CPU I could do a measurement on my TITAN3 system. You can see the result below.
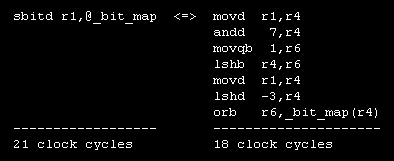
Fig. 1. Comparison between SBIT (left) and RISC style (right).
7 instructions in 18 clock cycles versus 1 instruction in 21 clock cylces : this is a desaster for CISC! The implementation of the bit instructions is incredible bad. At the end the engineers from National Semiconductor wrote an application note telling the customer "Hey, you should better use a RISC processor." . Unbelievable!
The M32632 executes the above example in 7 clock cycles for the SBIT and 13 clock cycles for the RISC style. That's how it should be.
The M32632 V2 executes the RISC style in 11 clock cycles. One clock cycle can be saved if the instruction "andd 7,r4" is changed to "andb 7,r4". This is possible because the final result is a byte operand.
INS
The INS instruction places a bit field of up to 32 bits at any bit position in memory or register. The instruction uses four operands : a source operand, a destination address, a bit offset and a length parameter. The opposite form of the insert operation is the extract operation for which the EXT instruction is defined.
I used this instruction to expand a black-and-white picture by one third on my TITAN3 system. Due to performance requirements I wrote this part in assembler. Later I tried a RISC style implementation of the INS instruction. Not surprisingly I found that this solution was faster. See the listing below.
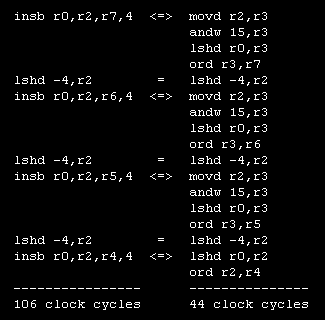
Fig. 2. Comparison between INSB (left) and RISC style (right).
The RISC style was much faster : 17 instructions in 44 clock cycles versus 7 instructions in 106 clock cycles. This is partly to the fact that the operation done is a simple merge (ord) instead of a real replacement. There are for sure programs where the difference is less. But I doubt that the INS instruction of the NS32532 could be faster than a RISC style implementation.
The INS code in the listing looks elegant. I tried my best to make the INS instruction faster in the M32632. The result is great: the M32632 V1 executes the four insb and three lshb opcodes in just 30 clock cycles. And how many clock cycles are needed for the RISC style ? Just 23. This is very fast and again much better than the NS32532. But it is also faster than the INS code. Reading the microcode again and again I didn't found a way to improve INS further. For this test the RISC style is the clear winner. Please note that all this numbers are valid if the programcode is in the instruction cache.
The new M32632 V2 take away three clock cylces in both styles: from 30 to 27 for INS and from 23 to 20 for the RISC code. The instruction "lshd -4,r2" is executed in one clock cycle. This is the first time that the M32632 decodes an instruction and an operand in the same clock cycle. Nearly all instructions with an immediate byte operand use this optimization.
The experience with NetBSD is that integer applications on the M32632 are 60% faster for the same clock frequency. One part of this gain is the improved architecture. The other part is for sure the much larger cache system.
Linpack
The Linpack program is used to evaluate the floating-point performance of computersystems especially supercomputers. It solves a system of linear equations and is in use since 1990. Todays versions of the software are very complex to test systems with hundred of thousands of CPUs. I took the original Fortran code in 1998 and translated it to Pascal. My compiler does not generate an optimized code, i.e. register allocation for variables is not done. Therefore the results are not as good as they could be. But you can see the increase in performance between the NS32016/NS32081 and the NS32532/NS32381.
The original Fortran code of the Linpack benchmark can still be found at http://www.top500.org .
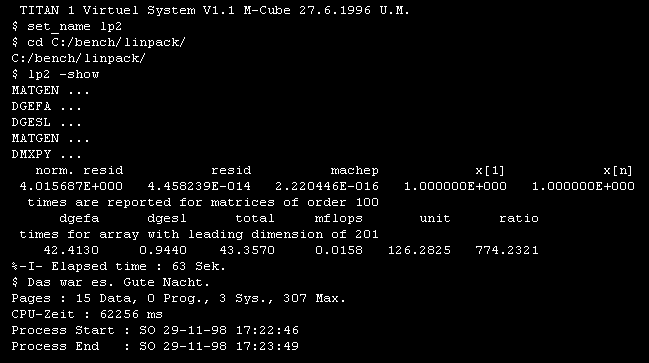
Fig. 3. Log file of NS32016/NS32081 doing Linpack in 1998.
The floating-point performance reported for the NS32016/NS32081 is 15.8 double precision kflops (64 bit floating-point operation per second). This number could be higher with program optimization. Nevertheless in the early 1980's this was a great result when you know that most microprocessors were just working on 8 bits. Please note that the memory consumption of this run was just 307 pages of 512 bytes or only around 150 kbytes. The column labeld "ratio" is remarkable too. It compares the floating-point result against the famous Cray-1, the first supercomputer.
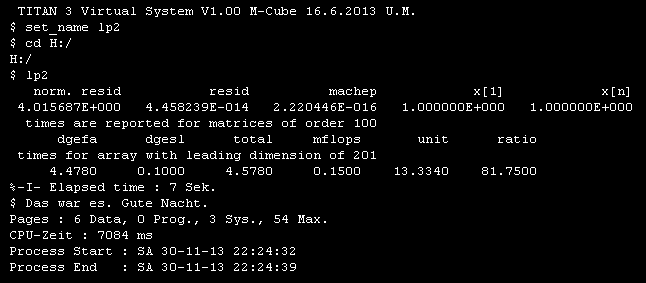
Fig. 4. Log file of NS32532/NS32381 doing Linpack in 2013.
The same program was running on my NS32532/NS32381 system in 2013. The performance is much higher : 150 kflops. Memory consumption is now 54 pages of 4 kbytes.
In 2010 I build my PC532E system. The operating system used is NetBSD. Luckily the gnu compiler suite of NetBSD provides a Fortran interface. Therefore I could compile the original Linpack code with optimization level -O3. Figure 5 below shows the result.
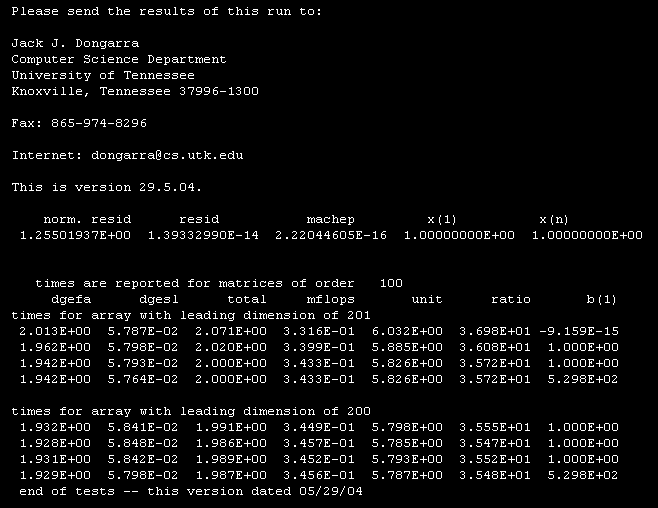
Fig. 5. Log file of PC532E doing Linpack in 2013.
Now the performance is more than double : 340 kflops. The result for the M32632 running at 35 MHz is known since January 2015. The number is ... 2.163 Mflops.
Wow! My guess was a factor of 4. But this is more than 6 times higher performance in this test. I got big eyes when I looked at the screen. Normally the experience tells you what you might expect. But in this very moment expectations were clearly surpassed.
The M32632 V2 running at 50 MHz achieves 3.02 Mflops.
Dhrystone
A well known integer benchmark is Dhrystone. The reference system for this benchmark was the VAX 11/780. A Dhrystone MIPS rating of 10 means that the measured system is 10 times faster than the reference system. The source code of the benchmark can be found at http://www.roylongbottom.org.uk/dhrystone%20results.htm . Currently Dhrystone version 2.1 is in use. The program was compiled on PC532E and PC632M. It needs some minor changes: "getc" changed to "getchar", deleting Microsoft DOS calls. This changes does not modify the critical part of Dhrystone. The following table shows the achieved results.
| Dhrystone 2.1 | NS32532: 25 MHz | M32632 V1: 35 MHz | M32632 V2: 50 MHz |
|---|---|---|---|
| non optimized | 4.02 DMIPS | 10.56 DMIPS | --- |
| optimized -O2 | 5.97 DMIPS | 16.12 DMIPS | 21.97 DMIPS |
M32632A
In Summer 2025 I looked at the statistic results of the SPICE compile run on NetBSD. The measurements showed tremendously many accesses of the DRAM for instructions and data page table entries. The idea of upgrading the cache system of the M32632 was already there for quite a while. But now the statistics gave this idea a push.
Two things could be done without touching the core of the M32632. The first thing was to change the MMU of the data cache from direct mapped to two-way set associative. The number of entries increases in this way from 256 to 512. Just to increase the number of entries would be a simpler change but less effective.
The second change is a new functionality inside the M32632: the instruction cache gets a second level. The reason not to increase the size of the first level instruction cache is the effort. A second level cache is a compromise. It shall be much bigger than the first level cache and it shall be much faster than a DRAM access. The FPGA of TRIPUTER has enough RAM to realize a 64 kByte 4-way set associative cache. A DRAM access needs 7 clock cycles. The second level cache needs only 2 clock cycles to deliver 16 bytes to the first level cache.
The effect of these enhancements is impressive:
| DRAM access for | M32632 | M32632A | Change |
|---|---|---|---|
| instruction fetch | 349,484,000 | 39,156,000 | -88.8 % |
| data page table | 14,520,000 | 868,000 | -94.0 % |
The compile time of SPICE was reduced by 7 % just by adding some more memory to the CPU. Because the M32632 reaches a new level of performance it should also get a new name: this design is now the M32632A.
This chapter was last modified on 15 November 2025. Next chapter: Getting M32632